


My NHL Betting Models Explained

My bet tracking now includes 4 models for picking moneylines/pucklines and 8 algorithms for over/under picks. I’m planning to share all the picks for this whole band of merry models when I’m giving out my own wagers, but instead of explaining how all of them work in every blog post, I’m going to do the comprehensive breakdown here so that it can be linked in all my future posts. It’s important to note that none of these models are playing with real money, these are all thought experiments in a spreadsheet. I have no immediate plans to build more because my portfolio worksheet is getting crowded.
If you’d like to read more about the first 3 years of this thought experiment, I wrote a 330-page book outlining the results from every angle. What worked, what failed. Lessons learned, market trends, team-by-team analysis. To read more, visit the Amazon store. My blog has been moved to Substack this season and I’ll be repeatedly encouraging everyone to sign-up for a free subscription to alleviate my dependence on Twitter for traffic. I’m concerned that Elon will follow through on his threat to charge everyone for Twitter and ostensibly destroy his own company. Subscribers receive an email notification each time a new post is published, and even if Twitter stays free, the algorithm likes to hide Tweets with links so you don’t leave.
The first model born was “Tailing History” which was simply intended to be a barometer for how well history was repeating if you were using the data in my weekly previews to make real wagers. Then something unexpected happened, it whopped my ass in week one so badly that it spawned a competition between the two of us. The rivalry was labelled “me vs myself” in a desperate attempt to prove that my own decision-making process is superior to a series of algorithms. Who should you trust? Me or myself? Even I don’t know the answer… You’ll need to rely on your own instincts to navigate these difficult waters.
I joked in my Week 1 Report that this must be how Viktor Frankenstein felt when he built a person out of spare parts and birthed a monster of unimaginable power. I don’t know what the minimum complexity threshold is to label a series of algorithms as “artificial intelligence”, but I’d like pretend this is an A.I driven portfolio that will eventually replace me as a handicapper and make my work obsolete. Dr. Frankenstein didn’t stop there, building the “Betting Venues” model a few weeks later which proved to be a far mightier beast. So impressive were the results that I had to run a diagnostic to make sure it wasn’t a mistake.

The table above shows how everyone is doing at each category. The data that feeds these beasts comes from my historical database of games, recording every moneyline and puckline since October 2019, and every over/under since October 2021.
Tailing History (aka “Tails”)
What would happen if you made a bet on every single game based on what was a better choice historically? This model was only intended to be a barometer of historical profitability replicability. Even if it lost money, the results would provide fodder for analysis about how trends are changing. The success or failure of the portfolio would at least provide some contextual relevance for my reports. People might bet their hard-earned money based on what worked in past seasons. Tailing History is keeping score.
All my previews and reports have the image below.

Tailing History uses the historical line range data week-to-week for its decisions, posted every Sunday in my previews. It looks up the line for each side, betting the one that made more money (or lost less). If the profit was less than $100, then it’s a minimum bet of $100. If it is $500 or higher, then it will be a max bet of $500. If the profit was $185, then the bet is $185. Very simple concept, and the fact that it’s still generating this much profit as the 4th quarter wraps is a big surprise. If it had been trained on the data from my first quarter preview instead, it would be down -$23,000, so clearly there’s something specifically useful about the week-to-week numbers.
Note: It consults a different set of input variables for back-to-backs, as it is forbidden from picking tired teams. The other models don’t care who played yesterday.

For over/under, all bet sizes are the same $100. If the total is 6.5, it bets the side that was more profitable (or lost the least) with that exact total in previous seasons. So, for the table above, it would bet Over for 5.5, 6, and 6.5 then under for 7. This is also a very simple concept that produced the best return of any model or algorithm making OU picks. Unders were very hot for the first 3 weeks, then overs got hot. Tails bet every under in week 3 then every over in week 4, so it did anticipate a scoring surge that actually happened. It just wasn’t expected to continue into week 5.
Betting Venues
Betting Venues was the “King of the Monsters” from the moment it was born. This concept had been bouncing around my brain for a couple weeks, and it only actually took me 30 minutes to build the model. Simply add up all the games between two teams in any given city since Oct 2019, sum the results of betting on every outcome, and pick a wager based on what was the most profitable choice historically. Frankly this one could also have been called “Tailing History”, but that name was already taken.
All that needed to be done was adding them up in my database, make a pick for each game, then feed it into my 2023/24 worksheet. It was actually able to register all its bets for the entire season without knowing any results (including games that already happened), because it doesn’t use any data from this season. It doesn’t care what the lines are, who is hot, who is cold, who is injured, who played last night, all variables it completely ignores. When the picks were fed into the games that had already happened, the result was astounding.
If Columbus is visiting Florida, it sums their previous meetings in that city.

Betting every home puckline -1.5 goals yielded $743. The minimum bet is $100, the max $500 (same for Tails and I). For this example, it is putting $500 on Florida -1.5 goals. Pretend that sum was -743, it would instead bet $256 on the HML. Its 3rd choice would be $100 on H+1.5. Make sense? Betting Venues also takes the average scores from those games to log an over/under wager. The total for FLA/CBJ was 6.5 and their average is 6.4, so it bet under. That’s the only information it’s using from the current season. However, it should be noted that it’s losing money on over/under picks. We’ll have to see if that trend sustains, but it might be poor at O/U selections.
Even after it started making ML/PL picks and I knew them all before logging mine, it still managed to kick my ass. Yeah, I should have been tailing it more often, but my belief in my superiority over a model that uses no data from the current season and doesn’t even care about the line compels me to zag. I’m using lots of data from the current season; Betting Venues doesn’t care. My information SHOULD be more valuable, but that’s not how it’s playing out. We’ll see where this goes. It’s having a bad week 7 because the underdog pucklines -1.5 goals are drying up.
Game Sum
Since my first two models don’t care at all about the current season, one more voice was needed on the advisory team that exclusively cares about the current schedule. This one is called “Game Sum”, which was named after my Game Summary worksheet that controls its decision matrix, where all my betting decisions are also made. Version 1.0 just sums up the category results for say Colorado road games and Seattle home games. The bet sizes on the graphic below were all $100. It pretends teams playing in Seattle are Colorado, and visa versa.

So, for this sample of games, betting $100 on every visitor -1.5 goals (whether favored or dog) yielded $800 profit. It has the same $100 minimum and $500 maximum as the other models, so anything over $800 just gets logged as $500. It sums VML, V+1.5, V-1.5, HML, H+1.5, H-1.5 results from games involving these teams, bets the most profitable. The first 3 weeks of its life went so poorly that it received an overhaul. The newest version is using the same input data, but is only looking at the last 30 days instead of the full season, and it’s bet sizes are now proportional to the probability of success, not the amount of profit that bet had generated (which Tailing History and Betting Venues both use). It was amusing that the new version had most of the same problems, it just wasn’t losing as much money. I’ll take that as a victory.
Game Sum will now be making OU picks. It takes every game in the last 30 days involving either of these two teams with the same opening OU total (6.5 goals for example). It adds up the results of betting every over and under when that’s the total, then bets the one that has been more profitable. Only last 30 days.
Shorting Travel
The final model built is Shorting Travel, based on the premise that teams struggle on their first game home from a long road trip. It only took a few minutes for me to run the numbers through my historical database, and the initial result that betting the road teams for these 424 games was a negative sum. But there was enough of a difference between the two sides to justify further analysis. Looking at the line ranges of the teams involved yielded an interesting result. Underdogs of +170 or higher produced a very large loss, and every other road moneyline range produced a profit. It was just longshots against good teams that skewered the initial analysis.
Another noteworthy observation from the road trip data was Pacific coast teams being among the best to short after returning from road trips. Logic suggests distance travelled might be an important factor. The next step was collecting the latitudes and longitudes of every NHL city (and European cities for a few neutral site games) and the formula for calculating distance between two points. This allowed me to compute distance travelled for every single game dating back to October 2019, including cumulative travel when a team is on the road. This gave me the data to build decision-making algorithms.
Explaining how this model selects bets is much more complex, but is built on a similar premise as Tails and BEV. This involved an entire afternoon of me feeding every travel scenario from the historical database into the profitability calculator, producing a similar line range profitability table. It decides what the bet will be for all the different ranges for the whole season, then makes a bet after the line is released.
The primary focus is home teams getting home from long road trips, but we also short road teams engaged on long expeditions. It took a few hours to go through every possible permutation (including a unique set of instructions for back-to-backs) but my diligence prevailed. It made no bet on 86% of games, but the ones it liked generated a very impressive 17% profit on the historical sample.
Seasonal Goalies
The new model added at the beginning of week 9, is betting which goalies are best “this time of year” plus or minus 20 days.

The image above is a screen shot of my seasonal data, with the 2 most probable starters from each team. I investigate game logs and manually assign a probability of either guy starting for either team. Those probabilities are multiplied by the goalie seasonal betting results, so if the game above was 100% confirmed Skinner vs Fleury, the weighted return of home -1.5 would be approximately $130. It bets whatever category has the best return. Makes sense?
Max Profit (formerly known as Megatron)
This one doesn’t have a theme of its own, it just adds up the performance of all the other models betting these teams in the last 30 days. The table below is copy/pasted out of my “Game Summary” worksheet and are the actual numbers for today’s Winnipeg-Boston game. In this case it made a max bet on the home team -1.5 goals because Betting Venues and Seasonal Goalies had success betting Jets -1.5 goals at home in the previous 30 days. Maximus had a terrible first week, then received a programing change and took off. Originally it was using the input data the models were using to make their picks, but then I switched to the profit (as it was using for over/under). For OU, it adds up all the profit of each algorithm betting results betting over or under for that total with these teams in the last 30 days. You’ll see that number in green at the bottom of my pick graphics, which is a different thing from the other “returns last 30 days”.

UPDATE: Max Profit won its max bet on Jets -1.5 goals vs Boston…
Goalies vs Teams
This one is self-explanatory. It simply adds up the results of betting either possible starter for both teams against this same opponent since October 2019 (which includes the current season), multiplies it by my educated guess of goalie starting probability, then bets the most profitable outcome. This one is currently on the bench and not sharing the picks because it struggled right out of the gate. Even if it never earns the right to share public picks, I’m very interested to add up its results betting each goalie to see if there’s an angle that it does work well that may be worth exploiting in the future. It does not make over/under picks.
Goalies Last 30 Days
This one is also self-explanatory except it does treat home and road as the same thing, ergo, its just the sum of each goalie’s betting results in the last 30 days, multiplied by starting probability. If Vasilevskiy is the confirmed starter for tomorrow’s game, it completely ignores the back-up’s results. This one does make over/under picks, but it will quite often bet the same as my “Betting Goalies” algorithm below, it just looks back a little farther. This one could end up replacing Betting Goalies on the Over Under Council.
Note: the first few picks of GL30 shared on my blog were actually the full season results. I had neglected to include the “last 30 days” indicator variable in the sumproduct function. But then it had a good first week, so if it starts nosediving, I may need to extend the range of the rearview mirror.
Expected Goals Last 30 Days
This model requires me to copy/paste expected goal numbers for every game from Natural Stat Trick (my historical database of games already had xGs), calculating average xGF and xGA for each team in the last 30 days. I’ve tried a few expected goal models previously that all failed miserably, but most of those used full season average. This is the first time I’ll be uploading new xG data daily to have an active model (instead of just running numbers in the summer). xGL30 had a good week one and was injected directly into the starting line-up.
The formula is pretty straight forward. You take expected goals for and against for each team in the last 30 days. Add one team’s xGF to the other’s xGA (then divide by 2), subtract their xGA + opponent’s xGF (divide by 2). From 0 to 0.5 it bets puckline +1.5 goals, from 0.5 to 1.5 it bets moneyline, greater than 1.5 it bets puckline -1.5 goals (which version 1.0 is barely betting). Bet size scaled to the input number (example: +0.01 equals a minimum bet). In this form it performed well week 1, but bet only a single game -1.5 goals. It was excellent with over/under, moneylines, and underdogs +1.5 goals, posting a loss on favorites +1.5 goals. It might be too conservative, do some tweaking might be done if it’s not maximizing returns.
After it’s strong first week, week two was bad. Dimitri Filipovic recently discussed on his podcast that modern offenses are rendering public xGoal models obsolete. There are too many false positives registered as high-danger that are not and too many actual high-danger that aren’t registered as such. xGL30 was especially bad at over/under picks week two (currently in dead last out of 12 OU models), which was its best strength in its first week. It might get dropped from the starting line-up if the slide continues.
The Over/Under Council
My Game Summary worksheet has always had a few different over/under algorithms for consultation, but relying on a primary formula for a majority of the selections. This was expanded for the current season, but some need at least 10 games to have been played, so they were all activated at different dates. Part of the problem with the previous advisory team is that there wasn’t enough variation in their opinions, and none were performing well across the full season. The chart below illustrates what happened with over/unders the first 6 weeks, and why everyone struggled.

Looking at my cumulative over/under chart vs betting all overs or unders paints a clear picture of what happened to me. Unders were booming, I was riding that wave, then unders suddenly collapsed, bringing me with them. Then after 2 weeks of chaos, I’m starting to latch on to overs (which may or may not sustain). The goal of diversifying the opinions on the Council is to get better accuracy on majority agreement, or at least be able to give better context when there is disagreement. By tracking the weekly results of all the different contributors, I’ll be able to see which combinations produce the best results when they are in agreement, and who should take the top job if Prime continues struggling.
My Tailing History and Betting Venues models each record a pick and have seats on the OU Council. “Tails” is doing the best out of all of us full season but has struggled the last 10 days. B.V had a good week 6 but a bad season thus far. Tails might be the best performing at OU, but it can’t take the mantle of Prime because it’s mostly just playing percentages and betting under 6.5 and over 6 in most cases. That’s not going to put me onto hot/cold teams and the margins are small. Instead of replacing my primary, I decided to add some new algorithms to the advisory team, then start tracking their weekly performance.
I’m going to be using a new graphic for my over under picks sharing more data. These show my entire OU Council member votes, and does share most of the averages being used to make the selection. It even counts the number of times these teams went over or under that total on the season, last 10, last 5, and last 8.
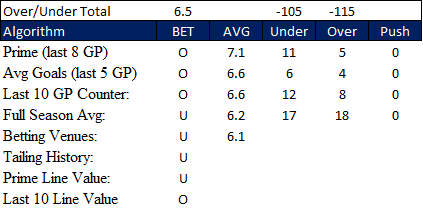
UPDATE: My lesser performing algorithms have been dropped from my pick graphics. Going forward there will only be 9. New models will need to earn the right to replace an existing Council member in order to have its picks shared.
OU Prime
My primary algorithm was born last All-Star break when the previous primary had been struggling for an extended period. Part of the problem with the 5-game averages was that one freak high scoring game could screw it up for the next 5 games; or a 1-0 game could lead to 5 consecutive under bets when the 1-0 game was a fluke goalie showcase. These were the problems I was observing in my game logs and it required a correction. The compromise was taking average for last 8 instead of last 5, but drop the highest and lowest scores then subtract it from the total. If it was greater than 0.75 or less than -0.75 goals, bet double.
The biggest issue with Prime right now is that it is dead last in performance for everyone on this list. The reason for that is it was activated right as unders were collapsing. I’m confident that it will find its footing once the variance starts to stabilize, assuming it ever does. But we have a few contenders to take the top job and I’m tracking how they all perform week-to-week.
5 Game Average Goals
My average goals last 5 games algorithm was activated in December 2021 right as the Omicron scoring boom was taking hold, and went on a very profitable run. It took the job from someone on this list, “10 game line value”, which was my very first over/under formula. It performed incredibly for the rest of that season (it did crash in the playoffs). But looking at its full season results for the current schedule, it is not doing any better than Prime, but still has a valuable voice alerting to possible emerging trends.
This one was my primary for roughly 1.3 seasons, until losing the job in a profitability investigation last All-Star break. The 5-game average is faster at reacting and profiting from emerging trends, but is also vulnerable to overreactions on temporary peaks/valleys.
Last 10 Games Counter
This one is very simple. It looks at the last 10 games for both teams and counts how many went over or under the total. In the example provided above, these two teams had gone over 6.5 goals 8 times and under 12 times. So, it bets the under. That’s it. Look at the game log and count. Anyone can do it. This one is interesting because it’s been part of my Game Summary worksheet for a long time, and it was one that I came to trust when the others were indecisive. One of the reasons is because last All-Star break when my previous primary was supplanted, this one was found to be right most often when the new Prime was wrong. Ties bet under, because the historical sample said so.
Full Season Average
Another very simple concept; average goals for each team full season. If the total is 6.5 and these teams average 6.4, bet under. This one has also been part of my Game Summary worksheet for a long time, and tends to get worse the deeper we get into the season because it barely reacts to shifting trends more games are played. This is actually what I was using for weeks 2 and 3 before enough games had been played to activate Prime. It’s one that I like having on the advisory team for context. I also have a full season counter and the data will be provided with my picks, but I’m not tracking the weekly results for that one.
Prime Line Value
This one is a simple concept, but less simple in its execution. It uses the same average goals last 8 games minus the min and max that informs Prime to estimate what the line should be for that total. If the modified average is 6 and the total is 6.5, then it punches -0.5 into a formula and produces a probability. That number is compared to the implied probability of the line, betting the side with more value. I have no idea if this is going to work long-term, but I’m interested to follow the results. It seems to love unders, which could either be a flaw in my formula, or there’s always value on unders because most people substantially prefer betting overs.
Last 10 Games Line Value
The very first algorithm I ever conceived back in the day was based on line value. What’s the probability of going over or under, and what’s the line? That did have some initial success, but was eventually replaced by the 5-gamer which crushed the Omicron scoring boom (goalies in Covid protocol). Once that took off and sustained deep into the season, the line value-based model was abandoned. Well now it’s making a comeback, count the number of times these teams went over or under that total in the last 10 games, compare that to the line, and bet the value.
We’ll see if “the Fallen” gets revenge. It’s a pretty simple concept. For example: let’s say both teams are 5-5 over and under that total in the last 10 games, then the over and the under should both be +100 (if we lived in a world with non-profit sportsbooks). If the over is -120 but should be +100, bet the under.
Betting Goalies
It requires me to look at game logs and predict probability of either starter for every game (which I’m recording and tracking), and it makes an expected projection based on 70% goals per game in a goalie’s starts during the team’s last 10 games, and 30% goals per game full season. Multiply probability of starting versus that projection. There’s an issue when one of the goalies hasn’t played, but I’m just doing a default pick using my own judgement in those cases (leaning over because goalies who haven’t played are higher risk of sucking).
Fair Line Estimator
If I haven’t explained the “fair line estimator” it’s a simple concept. If the home team is 6-3 at home and the road team is 3-6 on the road; add home wins to road losses, and you get 12 in 18 games. 12/18 is a .67 probability of victory. Flush that into the line converter and that should be -200. Same deal for the pucklines. Easy peasy.