


My Betting Models Explained (UPDATED)

This was overhauled on March 6, 2004 with more updates coming soon (hopefully).
My harem of models has grown to 15 who bet moneylines and pucklines, with another 14 19 who make over/under picks. Instead of explaining how all of them work in every blog post, I’m going to do the comprehensive breakdown here so that it can be linked in all my future posts. It’s important to note that none of these models are playing with real money, these are all thought experiments in a spreadsheet. I have no immediate plans to build more because my portfolio worksheet is getting crowded. Some might receive renovations, but no newbies are being added until playoffs.
This post is an updated version of my original Model Explainer.
The first model born was “Tailing History” which was simply intended to be a barometer for how well history was repeating if you were using the data in my weekly previews to make real wagers. Then something unexpected happened, it whopped my ass in week one so badly that it spawned a competition between the two of us. The rivalry was labelled “me vs myself” in a desperate attempt to prove that my own decision-making process is superior to a series of algorithms. Who should you trust? Me or myself? Even I don’t know the answer…
I joked in my Week 1 Report that this must be how Viktor Frankenstein felt when he built a person out of spare parts and birthed a monster of unimaginable power. I don’t know what the minimum complexity threshold is to label a series of algorithms as “artificial intelligence”, but I’d like pretend this is an A.I driven portfolio that will eventually replace me as a handicapper and make my work obsolete. Dr. Frankenstein didn’t stop there, building the “Betting Venues” model a few weeks later which proved to be a far mightier beast (for a while anyway). So impressive were the results that I had to run a diagnostic to make sure it wasn’t a mistake.
Eventually Tails and Betting Venues collapsed in the second quarter, so maybe that type of data is only really actionable early in the schedule before teams have established their new identity.
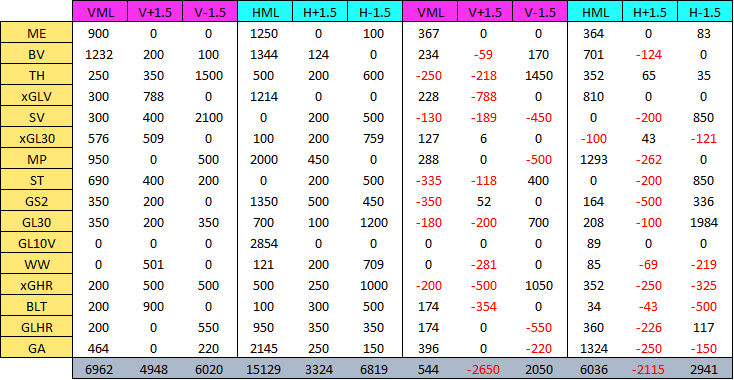
The new image with Q3 profit was added March 6 2024

One thing that deserves an asterix, some of the models above were fit to samples that included 3rd quarter games, and they need to prove themselves outside the laboratory before earning my trust. Some of those numbers above are artificially inflated and did not occur in real-time.
Grand Aggregator 2.0
The final model retrofit to the historical data is named my “Grand Aggregator” that adds up the total amount of money that all the models have wagered on each outcome and bets the largest position. It does not have an upper limit on bets, but will mostly be under $500. There’s a simple formula that uses the total wagered to approximate the bet size.
This was retrofit to the historical data at the end of Q3, and it was almost too easy to find the profit vectors. The retrofit version made the same bet (different sizes) in most cases. But when looking at the game-to-game numbers, it does get swayed towards picks sometimes by models who are performing brutally on that wager in the last 30 days. That led to the creation of the next aggregator.
Profit Aggregator
This one was not fit to the historical data and was only born on day one of the fourth quarter. It’s the exact same as the Grand Aggregator, but only adds up the bets from models who have generated >$0 from that bet with these teams in the previous 30 days. After one week it was better than the Grand Aggregator.
Chasing Profit Index
Max Profit 2.0 (aka Maximus, formerly known as Megatron)
This one doesn’t have a theme of its own, it just adds up the performance of all the other models betting these teams in the last 30 days (including itself and my picks). The table below was copy/pasted out of my “Game Summary” worksheet showing how much each model has wagered and profited with these teams last 30 days. Maximus goes by the biggest number at the bottom. The original model just used the raw input, but eventually that one collapsed, so a version 2.0 was created to ensure profitable wagers in 2023/24, fit more like a model than a formula, and it had a bad first week, decent second week. Stay tuned.
Fave Lover
Deceased.
Dog Lover
Deceased.
Me
My picks have been assimilated into the Chasing Profit index for my pick graphics.
Game Sum 2.0
It's the same premise as my old Game Sum model, but fit to a 4000-game sample. It adds up the betting results of each team's last 5 road or home games and makes picks on the results. The catch is, it doesn't always bet the team with the best results. It looks at the betting results from the last 30 days, but really only cares about which total is the largest. Once that’s established, there are a few secondary parameters.
Looking at the cerebral cortex, you’re welcome telling Icarus he’s flying too close to the sun. That’s a lot of compartments, but the samples within are comfortably large, at least the foundational pieces that most games will be funneled into.

Betting Trends Index
Tailing History 3.0 (aka “Tails”)
What would happen if you made a bet on every single game based on what was a better choice historically? This model was only intended to be a barometer of historical profitability replicability. Even if it lost money, the results would provide fodder for analysis about how trends are changing. Version 1.0 completely collapsed in the second quarter, so I tried fitting a new model to the season data using similar inputs, but not making proportional bets to those returns. It doesn’t always bet on the side producing the best returns.
This model is now up to version 3.0, retrofit to the previous 2 seasons of games. Tails 3.0 was one of my best Q3 models and still thrived outside the lab. We might have a winner there. Here is the cerebral cortex minus the picks, where you can see how many games were in each sample, plus total profit from the construction. Every so often it will bet the opposite of what’s been the best. It looks at +/- 7 days from today in the previous 2 seasons (adding up betting $100 on every outcome), and the last 7 days of the current schedule. So there is a little bit of 2023/24 seasoning in the feed.

Betting Venues 2.0
Betting Venues fast start helped feed my new obsession with model building, but alas the concept proved unstable over a larger sample of games. So during the all-star break it received an entirely new cerebral cortex.
Version 1.0 of Betting Venues was not fit to a large historical sample, it merely added up the results of the full sample, identified the most profitable pick, then selected that wager. That version excelled early, but inevitably collapsed over a larger number of games. Version 2.0 only cares about the previous 2 seasons, so that one can be tested for 2021/22, 2022/23, and the current 2023/24. The initial re-build (let’s call that version 1.5) used the largest possible sample (not just previous 2 seasons), but only made it through 40% of the sample before running out of profitable vectors (where I would have had to start betting teams who were bad against that opponent in that venue).
There were a few extra tools in my toolbox for this build, having totaled goal differential and expected goals for the previous meetings between those teams. Both those tools proved their value early in the investigation. 15 different variables were created, then checked to see which one had the highest correlation to who actually won the game. Expected GF% was the clear winner, even beating different permutations of the same input. It was also substantially better than win differential. So, a team having a good xGF% in their previous meetings was more important than winning all of them.
Actually explaining how this model makes picks is very difficult to do in laymen’s terms. It does make picks based on the line range of the teams involved, with different parameters for favorites and underdogs. The task was investigating every possible game state based on the xGF% and line range, with different bet selection instructions for each. Automating the model was a matter of assembling each permutation, the bet size formula, then setting up 1s or 0s as indicator variables to identify it which state each game belongs. I’m happy sharing a screen shot of what that looks like even if there’s enough data for an enterprising coder to extrapolate the whole model.

Basically, if you’re smart enough to reverse engineer my entire model using the image above, you’re probably smart enough to build your own. Not sure it’s worth the effort though, since you can just subscribe for free to my blog and frequently get the model’s picks delivered directly to your inbox. Also beware, some of those 1s and 0s are there to avoid potential minefields that risk collapsing the entire thing. Better to just get all the picks from me. The “yes” column highlighted in blue will produce a “1” for only a single game state. No more, no less. Technically there won’t be any GP=0 in the current season. That group was only necessary for 2021/22. This model was fit to 2.5 seasons (the clever coder may not have the historical data to fit the model).
Betting Loss Trends
This one was quite different from all the others, originally intended to a quasi-simple “zig zag” model (betting the loser of the previous game) with a special interest in playoffs, but by the end it placed a wager on nearly every game that has been played in the last 3 seasons producing a 17% return. The inputs were pretty simple: did each team win or lose their previous game, how many goals did they win or lose by, how many consecutive games has either team won or lost.
The finishing touches were applied this morning and I’ll be keeping the cerebral cortex a little closer to the vest because it was sensational at betting playoff games. The model construction started with the playoffs, producing a remarkable 40% return. Granted, that’s just 3 playoffs, so not a comfortably large sample. It’s trained to the small data it bet, and there’s no guarantee those parameters will carry over to future playoffs. After the playoff portion was completed, it’s focus was turned on 3.5 regular seasons, simply looking at whether the home or road team was streaking (bad or good), if they had won or lost the previous game, and by how much. Nearly every permutation revealed profitable wagers, though many had tiny margins.
It wagered nearly $1,000,000 fake dollars for a return of nearly $170,000. I’m very excited for this model, as it is already one of my best performers on the current schedule as well. I’m a little concerned that there are 60 sub-compartments to the decision matrix, but most of those have large samples inside because its spread over 4500 games. The automation is pretty complex, so there is still some error checking on the fly (I’d like to see the automated version sustain before trusting it too much). This model is being called “Betting Loss Trends” because that’s mostly what it does (though it does make picks based on teams winning their previous game or being on a winning streak, so it’s more than just Betting Losses).
Weighted Wins 2.0
Deceased
Betting Goalies Index
Goalies Last 30 Days
The original concept for this is self-explanatory. Just sum each goalie’s betting results in the last 30 days, multiplied by starting probability. If Vasilevskiy is the confirmed starter for tomorrow’s game, it completely ignores the back-up’s results. This one was born around the same time as Goalies vs Teams, and both models sucked together. When it was remodelled to bet the opposite side of the more profitable outcome, it produced a large profit. That was in the Hedge Fund for a while, but was retrofit to the previous 2 seasons and had a fantastic 3rd quarter. It’s now the leader of my Goalie Fund.
Shorting Goalies
The Shorting Goalies model does almost the exact same thing as Weighted Wins, except this one only bets moneylines, and flushed the input data through my estimated probability of each possible starting getting the call. If the probability of A or B is .7 and .3, then the input data would be almost identical if starter A actually starts 70% of their games. But if the back-up is 100% (confirmed) it completely ignores the results involving the primary starter. This one does not “weigh” the wins though in the long-term the weighted wins and actual wins are highly correlated.
It was originally in the Hedge Fund because it bets negative value, or the one it deems it the most over-priced. However it was removed from the Hedge Fund after Shorting Travel was expanded, because I needed a 3rd member of the new Goalie index.
Goalies Home/Road
This one takes the goalie stats from the last 10 home or road games for the home or road team, then flushed through expected starter probability. Pretty simple concept (more complicated building one of these for yourself, but here’s the cortex minus the picks to peak behind the curtain).

Expected Goals Index
Expected Goals Last 30 Days
This model requires me to copy/paste expected goal numbers for every game from Natural Stat Trick (my historical database of games already had xGs), calculating average xGF and xGA for each team in the last 30 days. I’ve tried a few expected goal models previously that all failed miserably, but most of those used full season average. This was my first season uploading new xG data daily to have an active model (instead of just running numbers in the summer), only using the last 30 days. There was an initial version that has since been replaced with a more detailed model that was actually fit to my historical sample of games, and accounts for back-to-backs. I’ll just show you screen shot of the bet selection matrix and let you figure it out.

There’s almost enough info there to build this model for yourself, bet sizes notwithstanding. However, Dimitri Filipovic recently discussed on his podcast that modern offenses are rendering public xGoal models obsolete. There are too many false positives registered as high-danger that are not and too many actual high-danger that aren’t registered as such. This model performed well over a larger historical sample, but not the second quarter of 2023/24, so maybe Dmitri is right and this concept is flawed with how teams are trying to score goals lately.
Expected Goals Line Value
When xGL30 version 2.0 was fit to the historical sample of games (with a 5.2% career return) a second was built to estimate what the betting line should be for that expected goals differential. It bets the option with the most “value”, and it does have a 3% career return, but also had a bad quarter. Problem is, I’m suddenly skeptical on making value-based picks, because if the line is off by a lot, there might be a good reason and maybe it’s not a good idea to pick that team.
This was the least worst expected goals model of mine in Q3, but they may all need to be recalibrated to 5v5 instead of all strengths, since evidently 5v5 is supposed to be more predictive.
Expected Goals Home/Road
This one takes a team’s last 10 home or road games, making bets based using expected GF% as the primary input, and team save/win percentages in those games. It will sometimes consult how profitable certain bets had been with these teams in that range when a tiebreaker is needed, but is mostly using xGF and SV%.
Below is the cerebral cortex (with a few different instructions for playoffs) minus the actual bet made. Also, this one shows how many picks were made on that compartment in the historical sample, and the profit.

THE HEDGE FUND
Shorting Value
This model was born as a version of the “fair line estimator” (aka FLE) model that uses the last 10 road games of the road team and last 10 home games of the home team to estimate what the line should be. Then bet the so-called “value”. When applied to the sample data, it was a giant loser in every possible category. It could not have been more wrong if I were deliberately trying to build a model to lose money. This then begged the question, if it’s THAT good at being wrong, what about a model that bets the opposite?
So, I flipped the picks, didn’t even change the bet sizes, and voila, big profit. As the other one was awful at everything, this one was good at nearly everything. On one hand, it should have been exciting to stumble upon a winning betting formula, but this had implications beyond giving out better picks in the future. Some of you may already be thinking it. I have been giving people betting advice based on this so-called “line value”, when it might actually be better to bet the opposite. How can betting against line value be so effective?
If a line is +160 and the records of the two teams dictates that the line SHOULD be +120, I’ve always looked at that as getting $40 of value on $100 bet. But perhaps I should have been dwelling more on why is that line off? What do the sportsbooks know that I don’t? They have more money, resources, man-power, etc, etc, etc, and I’m just a one man show (flying too close to the sun at times). There is also an expression among seasoned bettors called “a rat line” where a line is suspiciously off. Almost like the oddsmakers want you to bet that.
This concept is still new to me, so I’m following how this whole Hedge Fund performs in a larger sample. My observations thus far is they get hot from time to time, but also have some terrible nights. Not very reliable, with most members struggling Q3.
Shorting Value was updated in late February and refit to the previous 2 seasons. That did not improve it’s performance on new games.
Weighted Wins
This model required me to create an entirely new statistic for permanent tracking that could have other applications. The stat is easy to explain on a conceptual level, if you beat Colorado, that’s 1.5 wins. If you lose to Colorado, that’s 0.5 losses. Beat San Jose, it’s 0.5 wins, lose to San Jose, and it is 1.5 losses. We then compute a weighted win percentage for each team and compare it to the implied probability of the betting line. This is another model that “bets against value”, because it was profitable to do so. It was fit to second half data from the previous 2 seasons, ignoring 2021, producing an 8% profit.

The graphic above is the bet selection matrix from my Game Summary worksheet. I’m not going to bother explaining it, just a little inside glimpse for my fellow spreadsheet nerds. It does have a different set of decisions for back-to-backs, and behaves differently for dogs and favorites. It does have one specific set of circumstances with no upper limit. This one will bet the same side as Shorting Value in about 89% of games, as they are often looking at similar data and betting the negative value. Creating similar versions of the same thing was deliberate, as I’ll keep the better of the two for future seasons and scrap the loser.
This model might get terminated along with my Weighted Wins statistic. I still haven’t figured out how to make that useful.
Shorting Travel
Shorting Travel began on the premise that teams struggle on their first game home from a long road trip. It only took a few minutes for me to run the numbers through my historical database, and the first big observation was how many of the worst teams were Pacific coast. Logic suggests distance travelled might be an important factor. The next step was collecting the latitudes and longitudes of every NHL city (and European cities for a few neutral site games) and the formula for calculating distance between two points. This allowed me to compute distance travelled for every single game dating back to October 2019, including cumulative travel when a team is on the road. This gave me the data to build decision-making algorithms.
The primary focus is home teams getting home from long road trips, but we also short road teams engaged on long expeditions. This model was retrofit near the end of Q3 to the historical sample, but with some of my new tricks in my model arsenal was able to impose a mandate of more frequent picks. The original abstained in 82% of games. This one bets just under 82% of games. It’s one of the few models here that doesn’t have a bet every game mandate, but is still much more aggressive than the original.
Here is the cerebral cortex minus the bets.

Goalies vs Teams
Deceased
Hedge Fund Composite
Deceased
The “Small Council”
(Formerly Over/Under Council)
I’m no longer following the advice of a single algorithm for my choices. The algorithm formerly known as “Prime” is returning to its birth name “Avg Goals Last 8 GP Minus Max Min” which is a little too long for graphics.
My picks are now being guided by a “Small Council” of 5 members. Max Profit, Game Sum, Expected Goals L30, Goalies Last 30 Days, and Prime Avg L8 MMM (maybe sub-Prime is better). Not all of those voices are necessarily my best performing algorithms on the full season, but what makes them an ideal team is they’re all competent and use different data/methodology to do what they do. Too many members of my previous team voted the same way too often, which can prove costly when hit with shifting trends. I was going to have 6 members of my “Small Council”, but decided 5 was better because then there’s no ties. My bets will be scaled to their votes. 3-2 = $100, 4-1 = $200, 5-0 = $300.
They have a very high success rate when unanimously agreeing on the best bet. Despite building 6 new over/under betting models, I’m still using the Small Council as my primary advisors.
Avg Goals Last 8 Games Minus Max Min (Formerly Known as Prime)
My former primary algorithm was born last All-Star break when the previous primary had been struggling for an extended period. Part of the problem with the 5-game averages was that one freak high scoring game could screw it up for the next 5 games; or a 1-0 game could lead to 5-consecutive under bets when the 1-0 game was a fluke goalie showcase. These were the problems I was observing in my game logs and it required a correction. The compromise was taking average for last 8 instead of last 5, but drop the highest and lowest scores then subtract it from the betting total. If it was greater than 0.75 or less than -0.75 goals, bet double (Prime doesn’t bet double, only I do).
Game Sum
This one takes every game in the last 30 days involving either of these two teams with the same opening OU total (6.5 goals for example). It adds up the results of betting every over and under when that’s the total, then bets the one that has been more profitable. Only last 30 days. This is similar to Max Profit, except Maximus adds up model profit betting these teams/totals. Game Sum is just summing every over and every under.
Goalies Last 30 Days
This one uses the input data from the main model make over/under picks, similar to Betting Goalies but slightly smarter and looks back slightly farther. It made a profit in Q3 betting real-time games in its current form. It’s all about my prediction of which goalie will start, then creating expected goals against, add the team’s average goals for in the last 30 days, and is that above or below the total?
Expected Goals Last 30 Days 1.0
This one also has a pretty simple over/under method that is part of the Small Council. It just takes the average xGs (for and against) for both teams last 30 days (all strengths) if it’s above the total, bet over. This one bet every Q3 game in it’s current form and walked away with $109 profit. That’s substantially better than averaging goals from each team’s last 5 games, or 10 games, or full season (all of which are in my tracking).
Max Profit OU 1.0
For OU Maximus, adds up all the profit of each algorithm results betting over or under for that total with these teams in the last 30 days, bet the bigger number. Pretty simple. There is also a Max Profit OU model, but that one needs a little time to stretch its legs.
Over/Under Model Aggregator
I’m not up to 6 Over/Under models that sort games into compartments instead of using a basic formula. These are still being tested on real-world data for viability, but further explanation will be coming soon.
The Original Model
This one currently lacks an explanation, but here’s the brain.

The Leftovers
5 Game Average Goals
This one does exactly what you think it does. My average goals last 5 games algorithm was activated in December 2021 right as the Omicron scoring boom was taking hold, and went on a very profitable run. It took the job from someone on this list, “Last 10 GP Line Value”, which was my very first over/under formula. AvgL5 performed incredibly for the rest of that season (it did crash in the playoffs). This one was my primary for roughly 1.3 seasons, until losing the job in a profitability investigation last All-Star break. The 5-game average is faster at reacting and profiting from emerging trends, but is also vulnerable to overreactions on temporary peaks/valleys.
Full Season Average
Another very simple concept; average goals for each team full season. If the total is 6.5 and these teams average 6.4, bet under. This one has also been part of my Game Summary worksheet for a long time, and tends to get worse the deeper we get into the season because it barely reacts to shifting trends more games are played. This is actually what I was using for weeks 2 and 3 before enough games had been played to activate Prime. It’s one that I like having on the advisory team for context.
Betting Goalies
It requires me to look at game logs and predict probability of either starter for every game (which I’m recording and tracking), and it makes an expected projection based on 70% goals per game in a goalie’s starts during the team’s last 10 games, and 30% goals per game full season. Multiply probability of starting versus that projection. This was replaced by Goalies Last 30 Days which was similar put superior.
Tailing History
For over/under, all Tailing History’s bet sizes are the same $100. If the total is 6.5, it bets the side that was more profitable (or lost the least) with that exact total in previous seasons. So, for the table above, it would bet Over for 5.5, 6, and under for 6.5 and 7. This is also a very simple concept that produced a decent return given that it doesn’t care about the teams involved.
Grand Aggregator
This model also does the exact same thing for over under, just adds up how much every single model/algorithm bet on each outcome, then picks the largest position.
Fair Line Estimator
If I haven’t explained the “fair line estimator” it’s a simple concept. If the home team is 6-3 at home and the road team is 3-6 on the road; add home wins to road losses, and you get 12 in 18 games. 12/18 is a .67 probability of victory. Flush that into the line converter and that should be -200. Same deal for the pucklines. Easy peasy. Just be careful, seeing line value might mean pick the other side.